
Noss Rob -- 论文解读
本文全称《Superpixel alpha-expansion and normal adjustment for stereo matching》,在 Middlebury 视差数据集的评测网站中被命名为 NOSS ROB。本文基于超像素分割和图割算法提出了一套连续的双目视差预测方法,作者使用了一个3D的切向平面来参数化视差,并提出了两种算法来优化 Markov Random Field (MRF),分别是 superpixel $\alpha$-expansion 和 normal adjustment。本文方法在 Middlebury 3.0 评估中取得了很好的效果。
Introduction
本文是建立在 slanted patch matching 的方法基础之上的,在对于 patch match stereo 一文的分析中已经提到,它是对每个像素预测了一个浮点数的视差值,并对它预测了一个视差平面,但众所周知,我们是要在一个无穷多的空间中找到那个最优的视差平面,这就导致时间效率上和复杂的代价函数的问题。时间效率问题上一种优化方案是引入超像素或者网格(一个网格内包含多个像素)的概念,我们可以利用网格进行图像的分割并给每个网格分配同一个 label 值。然而一个网格内的像素当然不能简单地认为具有同样的视差值,而且最终的效果会很依赖于超像素分割的准确性。本文提出了一种立体匹配的方法,将超像素分割和法向调整相结合,来快速地为每个像素找到它的视差平面。
本文的主要创新点如下:
-
提出了一种 local $\alpha$-expansion 的基于超像素分割的方法来优化视差,利用了超像素中的每个像素有着相似的视差平面的性质
-
提出了法向调整的方法,在平坦的区域内能够传播较好的视差平面,避免因为缺少纹理信息而导致视差计算结果很糟糕
-
在 MiddleBury 3.0 的数据集上,实验结果显示在低纹理和有遮挡情况下本文都能取得很高的精确度
Method
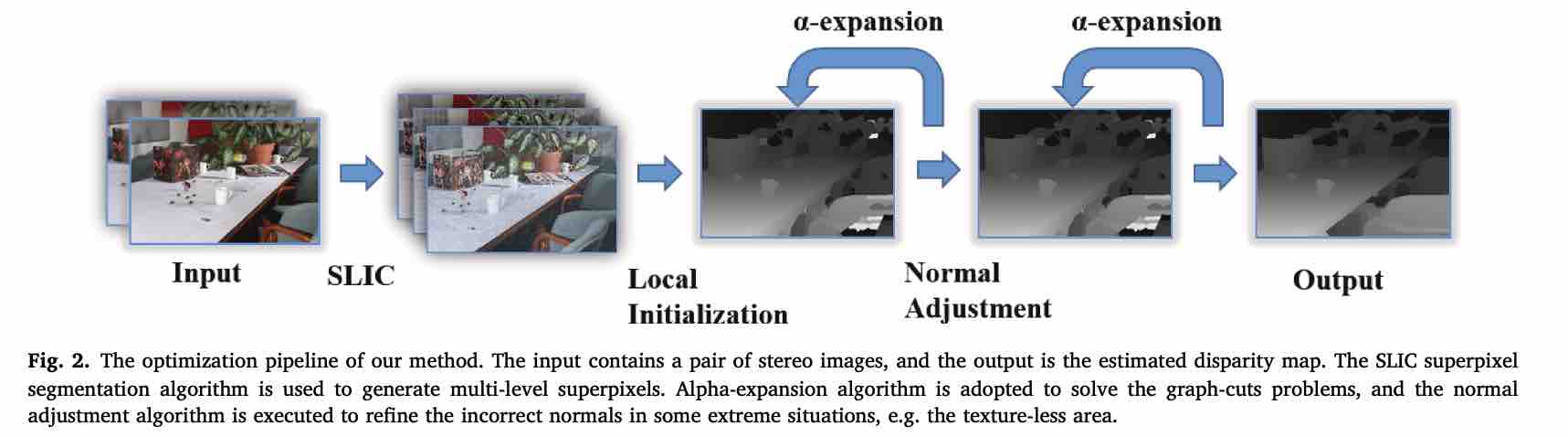
本文基本流程如下图所示,利用 SLIC 算法对图像获得3个尺度上的超像素分割,然后对图像进行初始化,利用 $\alpha-$expansion 算法进行迭代优化,然后用法向调整算法进行优化,最后生成视差图。
本文对于视差平面的建模和 Patch Match Stereo 中是一样的,在此不多赘述,可参考我的另一篇博文中对该文的详解。但本文除了和 PMS 中一样使用了一致性匹配代价之外,还定义了一个光滑匹配项,因此整体的能量函数如下:
其中 $f$ 是一个视差平面,$\phi$ 是熟悉的一致性匹配代价函数,在 PMS 中就被使用了。而 $\varphi$ 就是本文提出的光滑匹配项,它考察两个像素的视差和视差平面是否足够的接近,因为在相邻的区域中,像素的视差极有可能有相似的视差平面,或者视差平面变化幅度并不大,因此这个考虑是很合理的。光滑匹配项的公式如下:
$\bar{\varphi_{pq}}(f_p, f_q) = |d_p(f_p) - d_p(f_q)| + |d_q(f_q) - d_q(f_p)| $
其中 $\tau_{dis}$ 是一个用户自定义参数,表示当图像处于一个深度突变的情况下,不能因为光滑项而导致误判这种情况。
优化方法
-
初始化:流程和 PMS 类似,先通过 SLIC 算法获得分割成超像素的图像,对这些图像进行参数平面初始化,即和 PMS 一样赋予随机的视差平面法向量和深度,不同的是,本方法进一步进行了一些局部优化,对于每个像素进一步生成一个随机视差平面,并计算匹配代价,若 $\phi(p, f^{\prime}) < \phi(p, f)$ 那么就将 $p$ 点的视差平面更新为 $f^{\prime}$。
-
$\alpha-$expansion:在对不同尺度(分割为超像素)的图像初始化完毕后,用 $\alpha-$expansion 算法进行优化。流程如下:
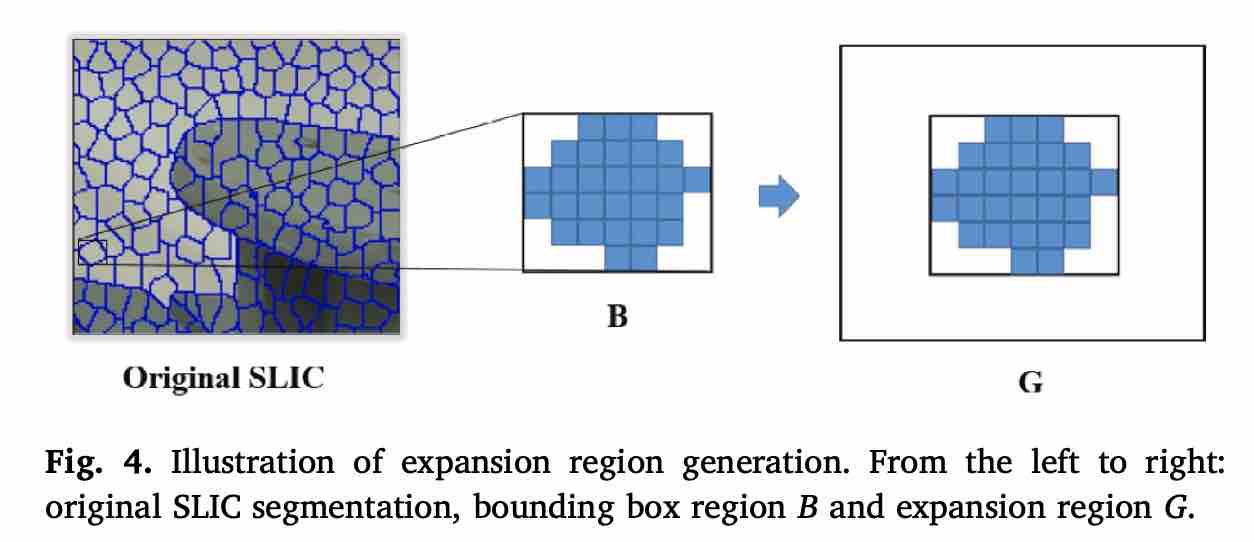
- 首先随机挑选一个超像素 $S$ 和其中的一个像素 $p$,然后生成一个新的视差平面 $\alpha = f_p + \Delta$
- 获取 $S$ 的包围盒,并对它进行拓展,拓展成 1.5 倍大小,称该范围为 G
- 优化如下公式:$f^{t+1} = \arg\min_f E(f), s.t. f_p \in \lbrace f_p^t , \alpha \rbrace , \forall p\in G $。实际上这是一个 0 或 1 的二项选择问题,在原本的 $f$ 和新提出的 $\alpha$ 中挑一个作为 $p$ 的新视差平面,而 G 的作用相当于给 $E$ 限定了一个窗口计算范围。
- 本文使用了多尺度的超像素图像,因此在每次迭代中,算法会轮流从最高尺度跑到最低尺度
- Normal Adjustment:然后就来到法向调整步骤。该步骤的主要思路是考察那些匹配代价较小(好)的超像素块和那些匹配代价较大(差)的超像素快,用好的平面去优化差的视差平面。步骤如下
- 对每个好的匹配的超像素块计算视差平面的平均加权法向量(将每个像素的法向量加权求和) $\vec{n_1}, \vec{n_2} … \vec{n_L}$
- 对于每个糟糕匹配的超像素块 $S_i$,调整其法向量为 $\omega \vec{n_i} + (1 - \omega)(\sum_{j=1}^Ln_j)/L$。说白了就是对”好“的向量和原本差的向量取一个线性插值。还有个额外的步骤,有了法向量以后,保证原本的视差不变,算出新的平面参数。
- 从流程图可以看出,在进行法向调整以后,依然要再进行数次 $\alpha-$expansion 的迭代获得更新后的视差
Conclusion
本文对为什么要用多尺度的超像素划分着墨不多,算法中关于这块有些模糊,有几种可能:一种是多尺度上分别计算,然后对最后结果投票;还有一种是,超像素仅供区域划分使用,但迭代过程中每个像素维护的视差和视差平面始终只维护了一组,每次迭代会在不同尺度超像素分割上都运行一次算法(后者可能性更大)。

本文通过实验论证了在 Middlebury 上取得了很好的效果(2018年 领先于其他方法),在 local $\alpha-$expansion 的基础上加上本文新提出的 normal adjustment 算法以后能够大幅提升准确性。