
Segment-Based Disparity Refinement (SDR) -- 阅读笔记
本文全称 “Segment-Based Disparity Refinement With Occlusion Handling for Stereo Matching”,是在立体视觉匹配问题中提出的一种直接对于 winner-take-all (WTA) 方法进行优化的的算法。本文采用已有的基于分割的算法,将图像分割成小块的超像素,并对于每个超像素分配一个视差平面,本文设计了一个两层的优化算法那来优化视差平面。本文的优化方法是一个纯粹的视差细化方法,其过程不需要立体像对之间的相关性信息。该文提出“匹配成本计算+视差细化”的框架是在较低计算成本下生成高精度视差图的一种可能解决方案。
Introduction
本文主要贡献有3点:
- 纯粹提出一个视差优化方法,直接依照色彩的参考图来优化WTA的视差图
- 建模了一个1D的MRF函数,根据视差分布建模了一个全新的 data term
- 一个前向平面向倾斜视差平面转变的一个框架
Method
本文的优化方法分为两层。首先我们通过 MC-CNN 生成一个匹配代价矩阵体(cost volume),那么对于某个坐标 $x$ 的像素,它的视差值可以通过 WTA 算法算出来:
可以看出就是一个简单的从 cost volume 中进行检索遍历。然后左视图会通过已有的图割方法分割成一列超像素,之后就能开始进行本文的优化处理。
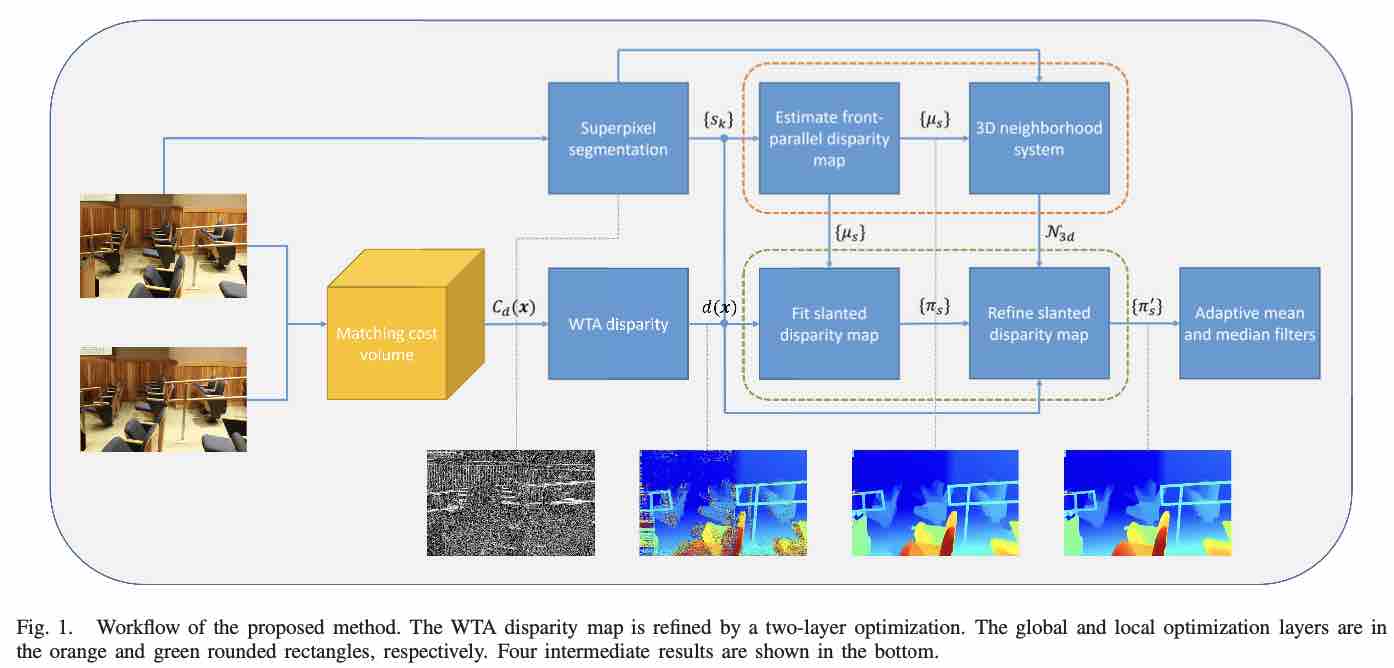
- Global Optimization 本文使用一个全局的 MRF 优化方法来预测一个前向平行的视差图,超像素会被处理为 graph nodes。我们的目标是将下述能量函数最小化
其中$\mu_s$ 是某个超像素的label,也就是这个超像素的平均视差值,$\Omega$ 表示所有超像素的集合,还有 $N$ 表示超像素相邻表。前面的 $\phi$ 表示 data term,后者的$\varphi$ 表示光滑项。
那么本文的数据项有什么特别之处呢,他是基于视差分布来设计的,而不像以往文章使用的匹配代价或者相似度计算等等。
Dispariry Distribution Interpretation
通常(普遍的超像素分割算法)我们假设在一个分割元中,视差是线性变化的,也就是在一个平面上,理想状态下,视差在这个超像素中应该是均匀分布的,因此本文用一个正太分布去衡量一个视差的 Norm。
方差越高表示这个超像素表示的平面越发倾斜。为了衡量视差是否可信,本文把所有超像素的视差用柱状图进行分类,然后来定义 data term。数据项评估的是视差中心的置信度,超像素的视差分布被分成了直方图,统计超像素视差落入直方图的数目,宽度为L。其中 $I$ 是一个条件判断。
光滑项更强调在一个领进超像素中,视差分布中心理应是相似的。$\omega$ 是一个颜色权重的影响系数,其公式已出现在众多的视差计算方法中,为 $\omega_{st} = e^{-| I(s) - I(t) |_2/\gamma}$,I 是一个超像素的凭据颜色值,L是两个相邻超像素的共享边界长度,T是一个度规或者半度规。
- Local Optimization 上一个步骤主要是估计超像素点的平均视差,得到一个前向平行的视差图,然后这一步通过将每个超像素赋值到一个平面上,对倾斜曲面的视差图进行细化。前平行斜面框架是通过双层优化实现的,上一步的MRF来全局优化前并行视差;局部过程,通过RANSAC平面拟合和基于概率的视差平面细化对倾斜曲面进行细化。