
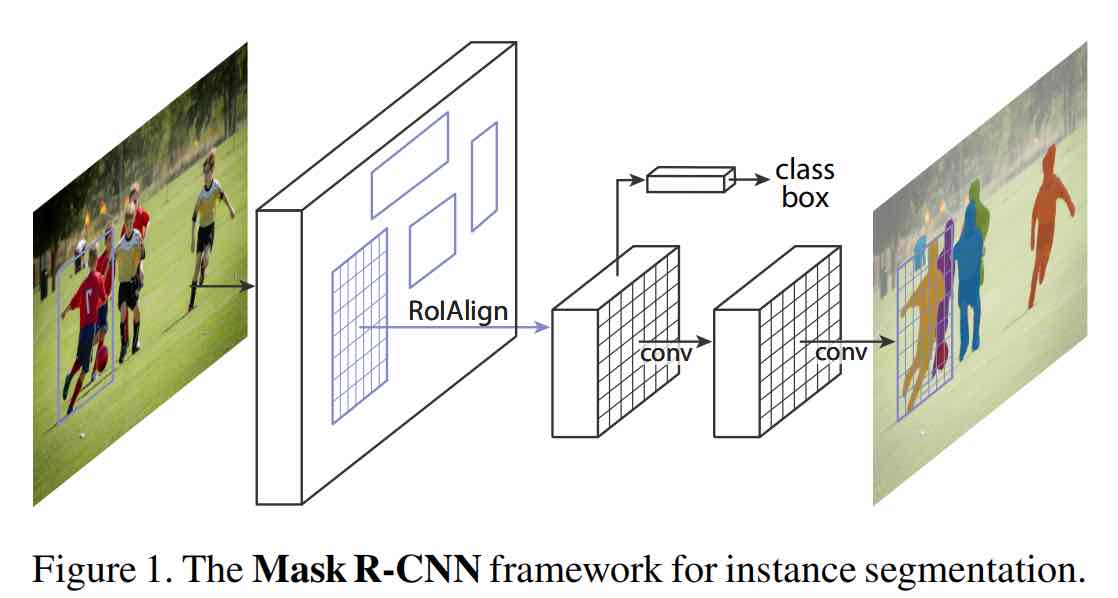
Mask R-CNN -- 阅读笔记
本文 Mask R-CNN 是图像分割领域中的一篇力作,本文提出了一种逻辑上简单灵活且易于泛化的实例分割的框架。从实现上,Mask R-CNN是基于Faster R-CNN的拓展,增加了一个用于预测物体mask的分支。本方法在效率上没有做提升,但可以达到5fps的帧率,该方法的可贵之处在于其良好的分割效果之外,能够相对简单地拓展到其他任务重,例如预测人体的姿态等。本文在当时能够发挥出优于当时大多数SOTA方法,如今依然是一种非常有效的图像分割的方法。
Introduction
Mask R-CNN是一篇结合了以往众多优秀工作的方法,其主要目的是完成图像分割中的实例分割这一任务,实时上基于其网络结构,它也能用于进行目标检测和语义分割。提到Mask R-CNN就不得不提到三个网络结构:
- Faster RCNN
- ResNet-FPN
- ResNet-FPN + Fast RCNN
本质上Mask R-CNN是多个网络结构的结合即 ResNet-FPN + Fast RCNN + Mask。
Faster RCNN
Faster R-CNN是两阶段的目标检测算法,包括第一阶段的Region proposal和阶段二的bounding box回归和分类。
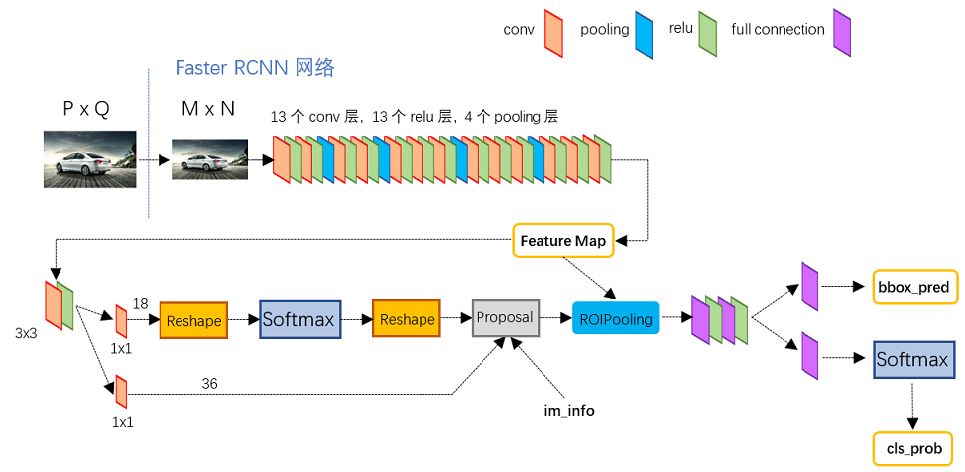
Faster RCNN使用CNN提取图像特征,使用RPN即region proposal network来提取出感兴趣区域即ROI,然后使用ROI pooling对这些ROI全部变成固定尺寸,再喂给全连接层进行Bounding box回归和分类预测。
ResNet-FPN
多尺度的检测在目标检测中变得越来越重要,对于小目标的检测尤其如此,包括yolo v3等最新的方法都开始加入多尺度的方法,那么在此引入Feature Pyramid Network即FPN网络,一种能够进行多尺度检测的方法。
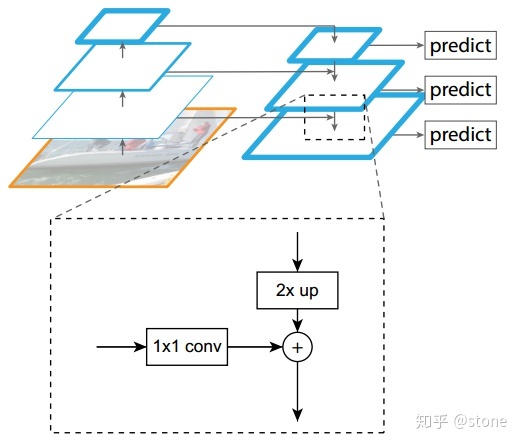
FPN结构自下而上,自上而下和横向链接三个部分,这种结构能够将各个层级的特征进行融合,使其同时具有强语义信息和强空间信息。事实上FPN是一种通用架构,可以结合任意骨架网络使用,可以从网络概念图中看出,左侧是一个特征提取网络,可以使用包括VGG,ResNet等backbone网络,Mask R-CNN一文中使用的是ResNNet-FPN的网络结构
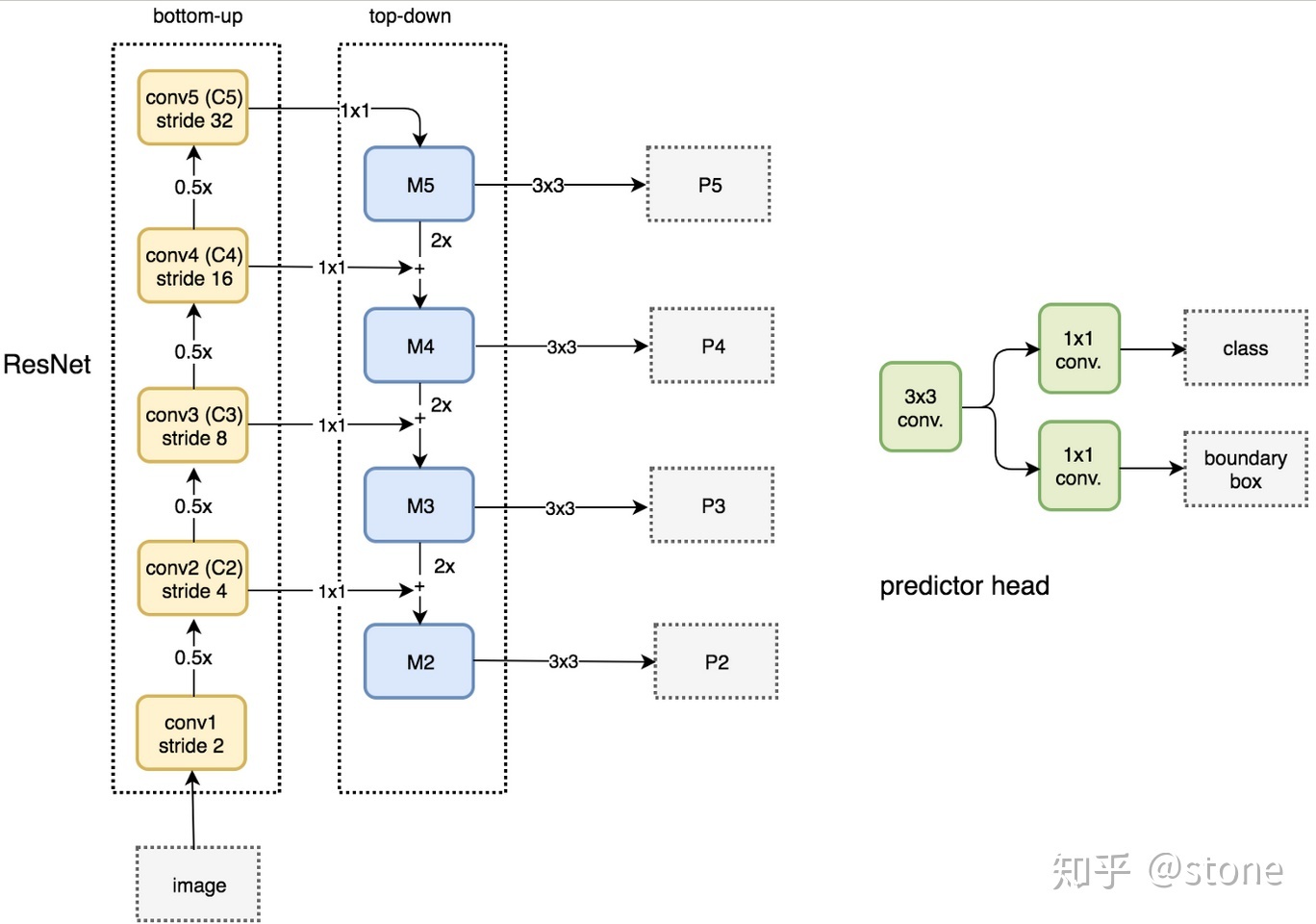
对于自下而上的路径,是特征提取的过程,和传统的VGG等卷积结构完成的工作没有区别,具体就是将ResNet作为骨架网络,根据feature map的大小分为5个阶段。自上而下是个上采样的过程,从最高层开始进行上采样,这里直接使用了最近邻上采样,而不是使用反卷积操作,一方面是操作简单且可减少训练参数。横向连接是将在自下而上的过程中生成的feature map和上采样结果中相同大小的feature map进行融合,当然这里的融合需要一定的操作,对下采样的结果进行 conv 1*1操作(降低通道数),不经过激活函数,将输出通道全部设置为相同的256通道,然后和上采样的feature map进行加和操作,在融合之后使用3*3的卷积核对特征进行处理。
ResNet-FPN + Fast R-CNN 将ResNet-FPN和Fast RCNN进行结合就是Faster R-CNN了,FPN说白了是用于产生多尺度的特征金字塔的,这个特征金字塔在经过RPN之后会产生很多的region proposal,但这些region proposal是从不同的金字塔层中诞生的,那么就需要在特征层中根据region proposal切出ROI进行后续的分类和回归,那么我们选择那个feature map进行切割最合适呢,通过如下公式决定宽w和高h的ROI从第几个feature map来切:
这里的224表示用于预训练的ImageNet图片的大小,$k_0$表示面积为$w\times h = 224\times 224$的ROI所应该在的层级,在本文中$k_0 = 4$,如果ROI的尺度比224小,那就要从更高分辨率的特征层比如$P_3$中去切割,该做法很合理,对于一个较小的ROI而言,低分辨率的特征层上的对应区域会很小导致信息过少,对于小目标的检测会更加有利。
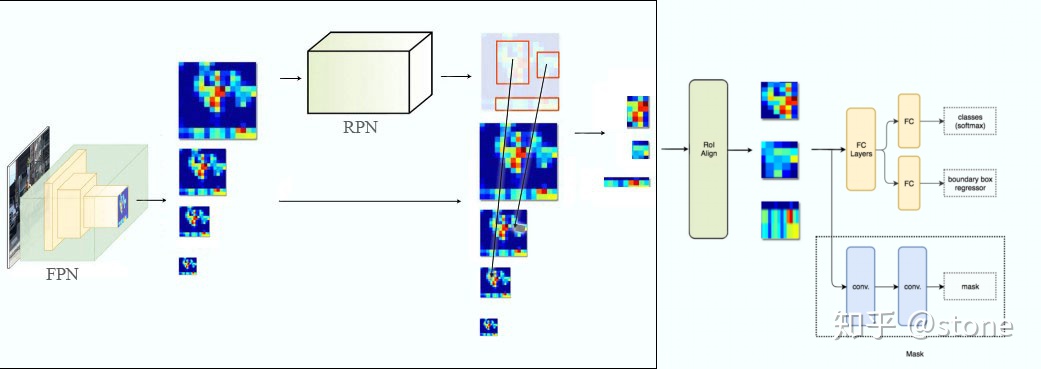
Method
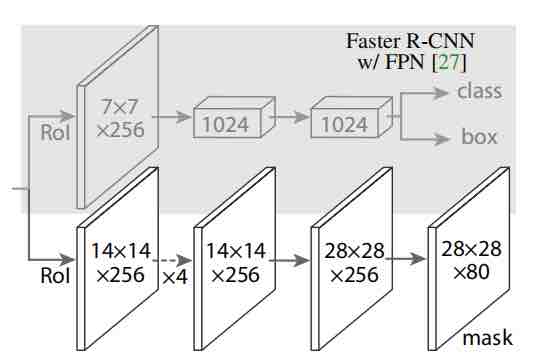
那么再进一步,将ResNet-FPN,Fast R-CNN和mask相结合就能得到Mask R-CNN,它的结构经过上述拆解就比较简单了,在ROI pooling添加卷积层进行mask预测的任务。总结一下Mask R-CNN的网络结构就是如下几点:
- 骨干网络ResNet-FPN,用于特征提取,ResNet可以替换为别的骨干网络 ResNet-50,ResNet-101,ResNeXt-50,ResNeXt-101等等
- 头部网络,包括边界框识别(分类和回归)+mask预测,头部结构如下所示
ROI Align
本文有一个很重要的改进,称之为ROIAlign,在Faster RCNN有一个问题是特征图和原始图像是不对准的,会影响检测精度,而本文提出了ROIAlign的方法代替了ROIpooling来保留大致的空间位置。
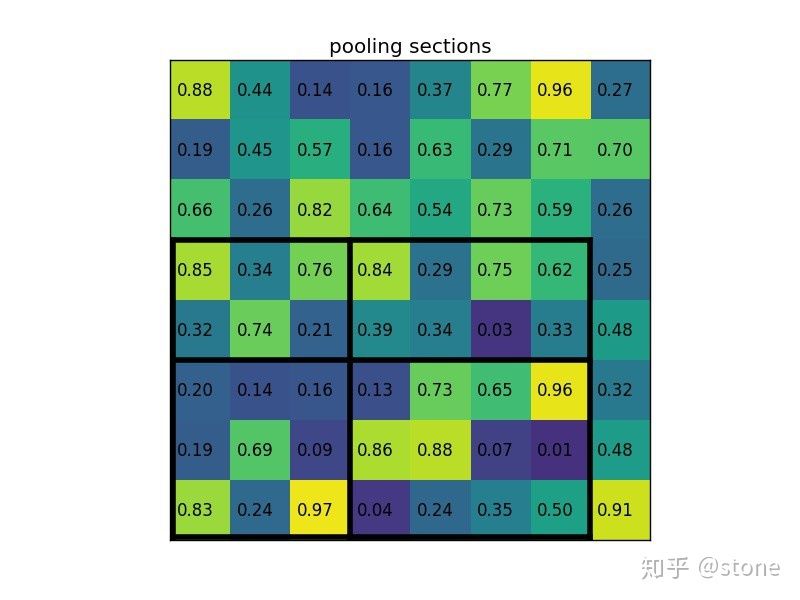
那么如何理解ROIpooling呢,举例来讲假设我们有一个$8\times 8$大小的特征图,我们要在这个feature map上得到ROI,并进行ROIpooling到$2\times2$大小的输出。假设ROI的bounding box为$[x_1, y_1, x_2, y_2] = [0, 3, 7, 8]$。将它划分为$2\times 2$的网格,由于ROI的长宽除以2无法整除,因此会出现每个格子大小不一样的情况,那么进行max pooling(在每个划分区域内取最大值)后就能得到$2\times 2$的最终输出。
那么ROI Align解决的是个什么问题呢?在Faster R-CNN中,有过两次整数化的过程:
- region proposal的xywh通常是小数,但是为了方便操作会把它整数化
- 将整数化后的边界区域平均分割成 $k\times k$个单元,对每一个单元的边界进行整数化
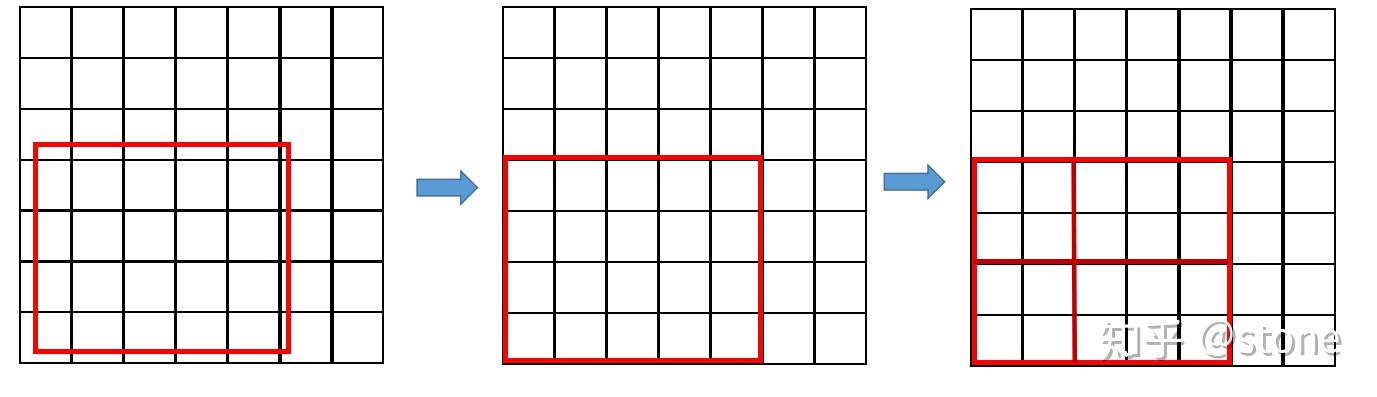
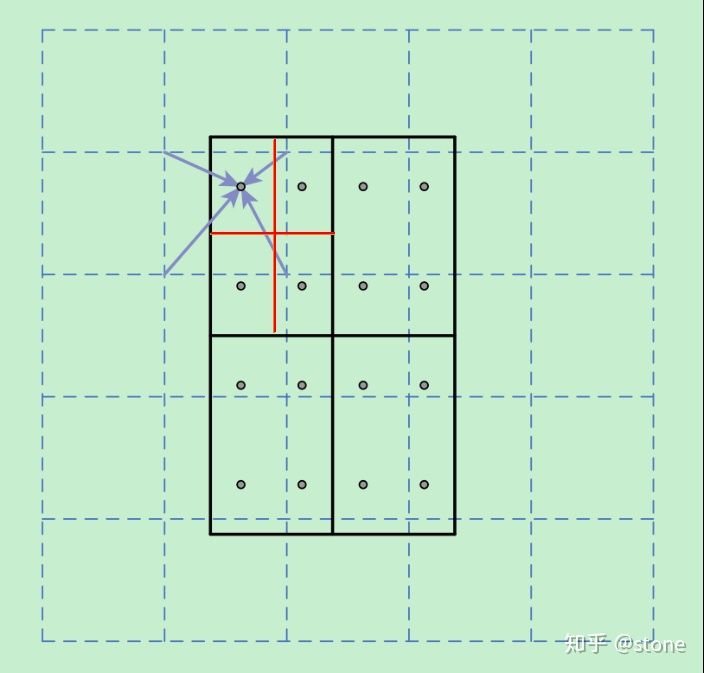
那么经过上述两次整数化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度(本文中描述为不匹配问题),ROI Align取消了整数化的操作,保留了小数,使用了双线性插值的方法获得坐标为浮点数的像素点上的图像数值,但在实际操作的时候ROI Align是经过重新设计的。举例说明ROI Align的操作,如果虚线部分表示feature map,实线表示ROI,这里将ROI切分为$2\times 2$的单元格,每个单元格采样点数为4,那么先将每个小单元格切分成4个小方格,每个小方格中心就是采样点,对该采样点像素进行双线性插值就能得到该点的值了,然后对每个单元格内的四个采样点进行maxpooling,就能得到ROIAlign的最终结果。
Loss
Mask R-CNN是一个多任务问题,其损失函数定义为$L = L_{cls} + L_{box} + L_{mask}$,前两者和faster rcnn的定义没有区别,需要具体说明的是mask的损失定义,假设我们有K个类别,那么mask分割分支的输出维度是$Kmm$,对于$m*m$中的每个点,都会输出K个二值的Mask(每个类别分别使用sigmoid输出),计算loss的时候并不是每个类别的sigmoid输出都计算二值交叉熵损失,而是该像素属于哪个类,哪个类的sigmoid输出才计算损失,测试的时候通过classification分支预测的类别来选择相应的mask预测,这样mask的预测就和分类预测彻底解耦了。
Ref
本文参考了知乎博文讲解:令人拍案称奇的Mask RCNN。