
Animation-type Stylizer
In recent years, there are many works studying fields of facial expression transfer and image stylizing, which have great potential in various application of industries, including filming, commercial and entertainment, etc. In this work, I will take advantage of the great feature controlling ability of StyleGAN network. Based on this characteristic, I’ll apply model-blending method based on transfer learning to achieve the target of image stylizing. The report and code can be found at the end of page.
Work Referred
If you are interested in machine learning, then you are likely to have heard about the GAN network. Many GAN-based networks have achieved great effects in generating images, like the StyleGAN network and its following series of works. The face images generated by StyleGAN can perfectly fool human eyes, and we can hardly tell whether the face is real or fake as it can contain very detailed information including skin textures and hair information.

GAN network, generative adverserial network, plays an important role in deep learning and becomes a popular method in unsurpvised learning in recent years. It can do amazing jobs when it comes to data generation and augmentation. The training process is novel compared to traditional neural network. We assume there two agents, generator and discriminator, and they are gaming with each other. Generator has no access to our dataset, and it has to fake an image from nothing, then showing it to discriminator. The goal of generator is to fool the discriminator and making it believe the image given is really from our real data set. On the other side, the discriminator know exactly how our real data set looks like and its job is to tell whether the image from generator is real or fake. As the training goes on, both generator and discriminator becomes more and more smart. Finally, we want the generator can produce “really fake” images that just look like real.
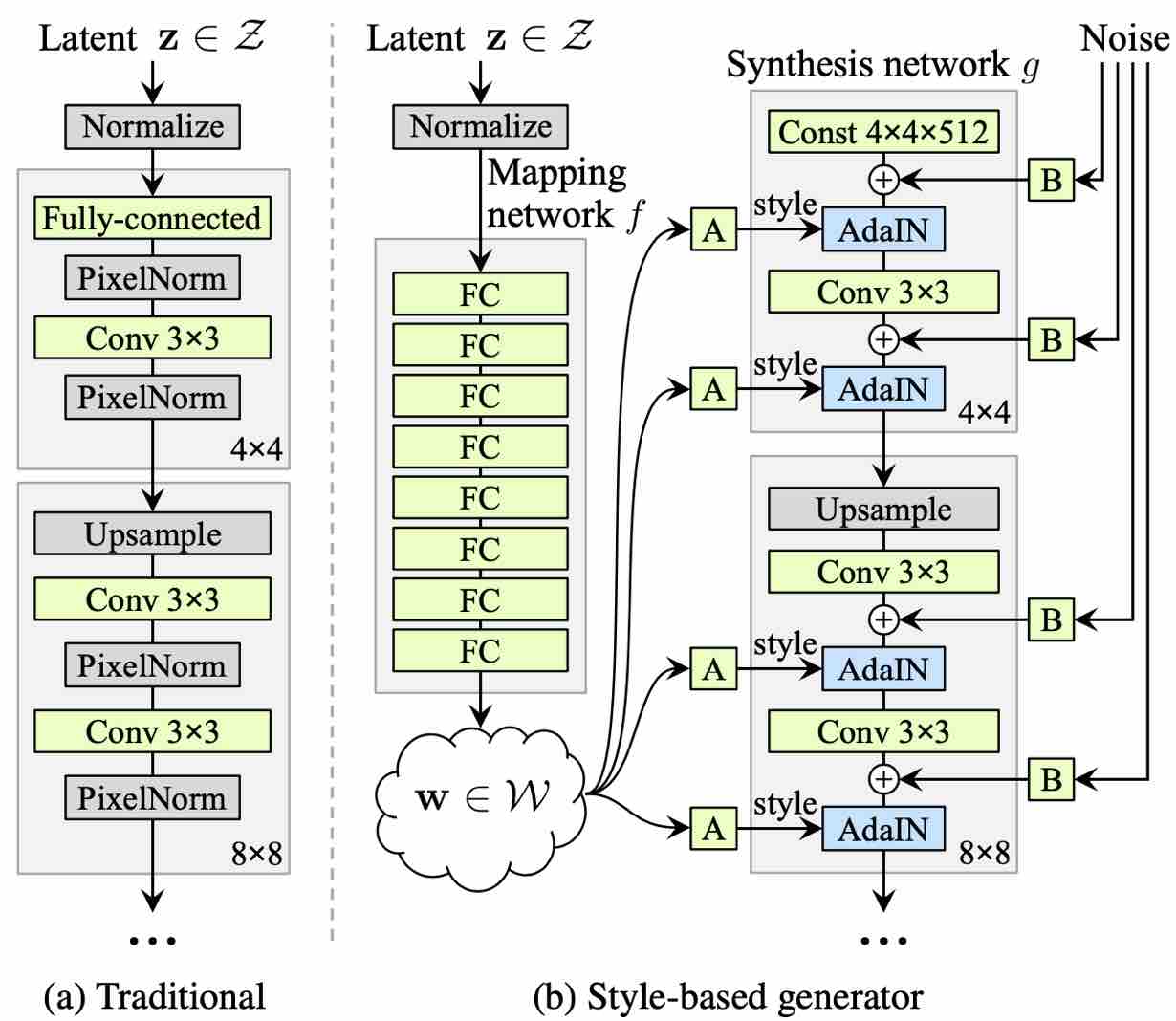
Based on this core training idea, there are lots of works study how to construct more efficient network models or design more specific training progress for target problem. StyleGAN network is one of them and the generator is designed to have two parts, including latent mapping and data generator.
Thanks to Nathan Shipley and his interesting experiments, we can notice an effect brought by convolutional layers in the generator network of different resolution. It is more likely that higer resolution layers can lead to more global patterns like color and texture, and lower resolution layers may control detailed patterns such as local expressions and shapes. Inspired by Nathan, what will happen if we combine layers from two pre-trained models?
Method
The overall progross can be divided into two parts, which are transfer learning and model blending. Transfer learning is working on a fine-tuned StyleGAN2 model and small set of data from another domain, such as animated faces or Disney-cartoon faces.
Fine-tuned learning
The advantage of transfer learning is the low requirement of data amount and training time, and we can make use of the pre-trained models. As we are training the facial image data, and the only difference is that we want to generate faces of certain styles instead of real human faces, we can assume the distributions of two domains of data are close to each other.
For training process, I passes about 350 images to StyleGAN2 model for training, based on the pretrained real face generator trained on FFHQ dataset. Consider the training time, workload and hardware, I trained for a 256x256 resolution StyleGAN2 generator. StyleGAN2 has its own training schedule, and I set the training starting point from 10000 timg in the code.
Model blending
After transfer learning, we should get a StyleGAN2 model that ran randomly generate images belonging to certain domains. Now we need to apply our metric to enable the model to sylize real human face.

As described in StyleGAN, the generator model contains convolution layers of different scales from $2^2\times 2^2$ to $2^8\times2^8$. The lower resolution layers are more likely to control detailed patterns, such as local expression, shapes, etc, in the generated images, while the higher resolution layers are more likely to generate macro information like texture and color of generated images. The blending metric is applying on the GAN model itself. As the transferred model is trained based on the real face model, we can expect that the weights in the network of these two models have continuous relation, and we can swap certain layers of one model into the other. The output model is expected to be able to generate style-mixed images containing both features of real faces and animated faces.
Experiments
Animated characters
The animated face images come from Danbooru2020, a large scale rowdsourcedand tagged anime illustration dataset. I randomly picked 500 images as trainingdataset for StyleGAN transfer training. The training data looks like the following.

After transfer learning, StyleGAN2 can automatically generate random animatedfaces. However, as the amounts of data is small, the network will easily go overfittingonce training for long epoch, and in my case, the generated images seem over-fit aftertraining 480 epochs. The following shows the results after training 160 epochs.

Now we have transfer learnt models and the original real face generator, andwe can apply model blending method to the two models to get a real-face stylizinggenerator. I blended the low resolution layers of real-face generator with the highresolution layers of anim-face generator. The swapping point is at $64\times64$ layer, and the results are shown below.

And in case you are interested how the original data looks like, the following images are from FFHQ256 pre-trained model.

Disney-type faces
The Disney-type faces are cropped by myself from Disney films. I temporar-ily collected 297 clips where Disney characters making facial expressions, and fromthem I randomly picked certain frames as the image dataset for StyleGAN2 transfertraining.

After transfer learning, StyleGAN2 can automatically generate random cartoonfaces. As the network will easily go overfitting once training for long epoch, I setthe training time relative short in this experiment, which is from 24 epochs from96 epochs. Observing from the results, the generated images seem to go overfittingafter 48 epochs. The following is results after 24 epochs training.

As the training happens, the face generated may lose more and more details as we can treat cartoon faces as simplified human faces.

Then we can apply model blending method to the results. In this experiment,I blend the models from 24 epochs to 72 epochs with original real face model, andtried to swap at different convolution layers from $16\times16$ to $64\times64$. The figurebelow shows the results generated the blend models. The real faces generated by the original model are like the example below.

From the results, we can see that the blend models can generate faces with features of cartoon faces magically when the blending point is at 64 and 32 resolution layers. The more cartoon model is blended, the more likely the generated faces to be close to a cartoon face. As we can see at blending point of 32 resolution, the blended model can already give a face that have large eyes and cartoon-like color and texture.

Code and Report
If you are interested in this experiment, you can access my full report here. The training is happening in colab, and the github code can be found here.